实验指导 step1:词法分析、语法分析、目标代码生成
第一个步骤中,MiniDecaf 语言的程序就只有 main 函数,其中只有一条语句,是一条 return 语句,并且只返回一个整数(非负常量),如 int main() { return 233; }。
第一个步骤,我们的任务是把这样的程序翻译到汇编代码。 不过,比起完成这个任务,更重要的是你能
- 知道编译器包含哪些阶段,并且搭建起后续开发的框架
- 了解一大堆基本概念、包括 词法分析、语法分析、语法树、栈式机模型、中间表示
- 学会开发中使用的工具和设计模式,包括 gcc/qemu、词法语法分析工具 和 Visitor 模式*
词法分析
读内容 *词法分析*
MiniDecaf 源文件 --------> 字节流 ----------> Tokens --> ...... --> RISC-V 汇编
词法分析(lexical analysis) 是我们编译器的第一个阶段,实现词法分析的代码称为 lexer , 也有人叫 scanner 或者 tokenizer。
它的输入 是源程序的字节流
如
"\x69\x6e\x74\x20\x6d\x61\x69\x6e\x28\x29\x7b\x72\x65\x74\x75\x72\x6e\x20\x30\x3b\x7d"。上面的其实就是
"int main(){return 0;}"。它的输出 是一系列 词(token) 组成的流(token stream)1
上面的输入,经过 lexer 以后输出如
[关键字(int),空白、标识符(main),左括号,右括号,左花括号,关键字(return),空白、整数(0),分号,右花括号]。
如果没有词法分析,编译器看到源代码中的一个字符 '0',都不知道它是一个整数的一部分、还是一个标识符的一部分,那就没法继续编译了。
为了让 lexer 完成把字节流变成 token 流的工作,我们需要告诉它
有哪几种 token
如上,我们有:关键字,标识符,整数,空白,分号,左右括号花括号这几种 token
token 种类 和 token 是不一样的,例如 Integer(0) 和 Integer(222) 不是一个 token,但都是一种 token:整数 token。
对于每种 token,它能由哪些字节串构成
例如,“整数 token” 的字节串一定是 “包含一个或多个 '0' 到 '9' 之间的字节串”。 不过这没考虑负数,后面 “语义检查” 会继续讨论。
词法分析的正经算法会在理论课里讲解,但我们可以用暴力算法实现一个 lexer。 例如我们实现了一个 minilexer(代码)当中, 用一个包含所有 token 种类的列表告诉 lexer 有哪几种 token(上面第 1. 点), 对每种 token 用正则表达式描述它能被那些字节串构成(上面第 2. 点)。
细化到代码,Lexer 的构造函数的参数就包含了所有 token 种类。 例如其中的 TokenType("Integer", f"{digitChar}+", ...) 就定义了 Integer 这种 token, 并且要求每个 Integer token 的字符串要能匹配正则表达式
[0-9]+,和上面第 2. 点一样。
你可尝试运行 minilexer,运行结果如下(我们忽略了空白)
$ python3 minilexer.py
token kind text
Int int
Identifier main
Lparen (
Rparen )
Lbrace {
Return return
Integer 123
Semicolon ;
Rbrace }
本质上,token 是上下文无关语法的终结符,词法分析就是把一个字节串转换成上下文无关语法的 终结符串 的过程。
不过 token 比单纯的终结符多一个属性,就是它的字符串(如 Identifier(main) 的 main),你可以说 token 是有标注的终结符。
语法分析
词法分析 *语法分析*
字节流 ----------> Tokens ----------> 语法树 --> ...... --> RISC-V 汇编
语法分析(syntax analysis) 是紧接着词法分析的第二个阶段,实现语法分析的代码称为 parser 。
- 它的输入 是 token 流
就是 lexer 的输出,例子上面有
- 如果输入没有语法错误,那么 它的输出 是一棵 语法树(syntax tree)
比如上面的程序的语法树类似
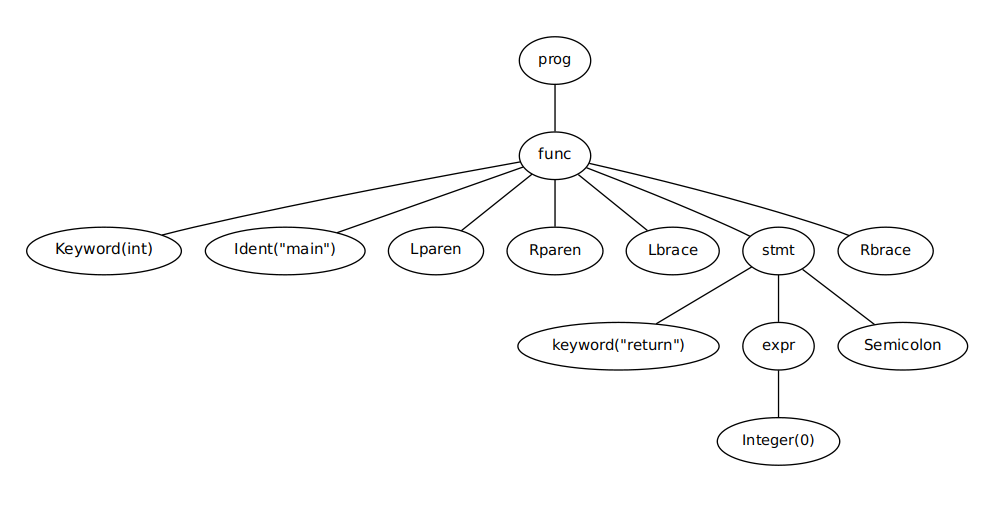
编译原理的语法树就类似自动机的 语法分析树,不同的是语法树不必表示出实际语法中的全部细节。 例如上图中,几个表示括号的结点在语法树中是可以省略的。
语法分析在词法分析的基础上,又把程序的语法结构展现出来。
有了语法分析,我们才知道了一个 Integer(0) token 到底是 return 的参数、if 的条件还是参与二元运算。
为了完成语法分析,肯定要描述程序语言的语法,我们使用 上下文无关语法 描述 MiniDecaf。
就这一步来说,MiniDecaf 的语法很简单,产生式大致如下,起始符号是 program。
program : function
function : type Identifier Lparen Rparen Lbrace statement Rbrace
type : Int
statement : Return expression Semicolon
expression : Integer
一些记号的区别: 形式语言与自动机课上,我们用大写字母表示非终结符,小写字母表示终结符。 这里正好相反,大写字母开头的是终结符,小写字母开头的是非终结符。 并且我们用
:而不是->隔开产生式左右两边。
同样的,语法分析的正经算法会在课上讲到。 但我们实现了一个暴力算法 miniparser(代码)。 这个暴力算法不是通用的算法,但它足以解析上述语法。 你可尝试运行,运行结果如下(下面输出就是语法树的先序遍历)
$ python3 miniparser.py
program(function(type(Int), Identifier(main), Lparen, Rparen, Lbrace, statement(Return, expression(Integer(123)), Semicolon), Rbrace))
前面提到,语法树可以不像语法分析树那样严格。 如果语法树里面抽象掉了程序的部分语法结构,仅保留底下的逻辑结构,那样的语法树可以称为 抽象语法树(AST, abstract syntax tree);而和语法完全对应的树称为 具体语法树。 当然,AST 和语法树的概念没有清楚的界限,它们也常常混用,不必扣概念字眼。 上面 miniparser 的输出就是一棵具体语法树,而它的抽象语法树可能长成下面这样(取决于设计)
$ python3 miniparser-ast.py # 假设有个好心人写了 miniparser-ast.py
Prog(funcs=[
Func(name="main", type=("int", []), body=[
ReturnStmt(value=Integer(123))
])
])
语义检查
有时我们会用 语法检查 这个词,因为语法分析能发现输入程序的语法错误。 对应语法检查,还有一个词叫 语义检查。 它检查源程序是否满足 语义规范,是否有 语义错误,例如类型错误、使用未定义变量、重复定义等等。
就 step1 来说,我们的语义规范如下。显然,我们要检查的就只是 Integer 字面量没有越界。
1.1. MiniDecaf 的 int 类型具体指 32 位有符号整数类型,范围 [-2147483648, 2147483647],补码表示。
1.2. 编译器应当只接受 [0, 2147483647] 范围内的整数(step2 会添加负数支持)。 如果整数超过此范围,编译器应当报错。
1.3. 因为只有一个函数,故函数名必须是 main。
完整的语义规范应包含如下几点。指导书只会包含关键点,避免叙述太冗长。
什么样的代码是 不合法 的。对于不合法的代码,编译器必须报错而不是生成汇编。
例如 step1 中,如果程序中 int 字面量超过上面的范围,那编译器就应该报错 "int too large"。 如果函数名不是 main,也应该报错。
合法程序中,每个操作的行为应该是什么样的。
例如 return 执行结果是:对操作数求值并作为返回值,然后终止当前函数执行、返回 caller 或完成程序执行。
对于合法程序,你生成的汇编须和 gcc 生成的汇编运行结果一致。
什么样的行为是 未定义 的。如果代码在运行时展现未定义行为,编译器不用报错,但它后果是不确定的。
例如有符号整数溢出、数组越界、除以零都是未定义行为。
测例代码不会有未定义行为,不必费心考虑。
语义检查的实现方式很灵活,可以实现成单独的一个阶段,也可以嵌在其他阶段里面。 第一种方式在后面的实验中有,但就 step1 而言,检查 int 范围的工作直接放进 parser 或 lexer 中就行了。 例如我们就把他放到了下一个阶段:目标代码生成里。
目标代码生成
词法分析 语法分析 *目标代码生成*
字节流 ----------> Tokens ----------> 语法树 ----------------> RISC-V 汇编
生成 AST 以后,我们就能够生成汇编了,所以 目标代码生成(target code emission) 是第三也是最后一个步骤,这里目标代码就指 RISC-V 汇编。
- 它的输入 是一棵 AST
- 它的输出 是汇编代码
这一步中,为了生成代码,我们只需要
- 遍历 AST,找到 return 语句对应的
stmt结点,然后取得 return 的值, 设为 X 2 - [可选] 语义检查,若 X 不在 [-2147483648, 2147483647] 中则报错;并且检查函数名是否是 main。
- 打印一个返回 X 的汇编程序
针对第 1. 点,我们使用一个 Visitor 模式来完成 AST 的遍历。 同样,我们有一个 minivisitor(代码)作为这个阶段的例子。
Visitor 模式比简单的递归函数更强大,用它可以让以后的步骤更方便。 Visitor 模式速成请看 这里
针对第 2. 点,我们用 (RISC-V) gcc 编译一个 int main(){return 233;} 就能知道这个汇编程序什么样。
gcc 的输出可以简化,去掉一些不必要的汇编指令以后,这个汇编程序长成下面这样。
编译方法请看 工具链使用。 汇编代码中,li 加载常数 X 到 a0 寄存器。RISC-V 约定 a0 保存返回值,之后 ret 就完成了 return X 的工作。
.text
.globl main
main:
li a0,X
ret
运行 minivisitor,输出就是模板中的 X 被替换为了一个具体整数
$ python minivisitor.py
.text
.globl main
main:
li a0,123
ret
至此,我们的编译器就完成了,它由三个阶段构成:词法分析、语法分析、目标代码生成。 每个阶段都有自己的任务,并且阶段和阶段之间的接口很明确:字节流、token 流、AST、汇编代码。
任务
- 在不同输入上,运行 minilexer, miniparser 和 minivisitor。
- 浏览它们的代码(不用完全看懂)
思考题
以下思考题六选四,在实验报告中回答。
- minilexer 是如何使得
int被分析成一个关键字而非一个标识符的? - 修改 minilexer 的输入(
lexer.setInput的参数),使得 lex 报错,给出一个简短的例子。 - miniparser 的算法,只有当语法满足什么条件时才能使用?
- 修改 minilexer 的输入,使得 lex 不报错但 parser 报错,给出一个简短的例子。
- 一种暴力算法是,只做 lex,然后在 token 流里面寻找连续的
Return,Integer和Semicolon,找到以后取得Integer的常量 a,然后类似上面目标代码生成。这个暴力算法有什么问题? - 除了我们的暴力 miniparser,形式语言与自动机课中也描述了一种算法,可以用来计算语法分析树。请问它是什么算法,时间复杂度是多少?
总结
本节引入了很多概念,请仔细消化
- Lexer
- Token
- Parser
- 抽象语法树
- 语义检查
- 目标代码生成
- Visitor
备注
1. 之所以说“流”而不是“列表”,是因为不一定 lexer 一下就把所有的 token 都拿出来,还可以按照后续阶段的需要按需返回 token。 ↩
2. 当然,就第一个步骤来说,你直接找到 Integer 节点也可以 ↩