step5 实验指导
本实验指导使用的例子为:
int main() {
int x = 2026;
return x;
}
词法语法分析
针对局部变量定义和赋值操作,我们需要设计 AST 节点来表示它,给出的参考定义如下(框架中已经提供):
| 节点 | 成员 | 含义 |
|---|---|---|
TInt |
无 | 整型 |
Identifier |
名称 value |
标识符(用于表示变量名) |
Assignment |
同 Binary |
赋值运算 |
Declaration |
类型 var_t,标识符 ident,初始表达式 init_expr |
变量声明 |
请注意,赋值操作是一种特殊的二元运算,因此可以将它合并到 Binary 节点里,也可以单独设置一类节点继承 Binary 类来处理它。
语义分析
从本节开始,我们需要在语义分析阶段对局部变量的规范进行检查。具体来说,我们需要名为符号表的数据结构。符号表的实现已经在框架中给出。因此,你只需要修改语义分析部分的代码,在必要时调用符号表的接口即可。
在符号表构建过程中,我们要按照语句顺序,逐一访问所有变量定义声明。在访问变量声明时,我们需要为该变量赋予一个变量符号,并将它存入符号表中。由于变量不能重复声明,在定义变量符号前需要在符号表中检查是否有同名符号。
类似地,在访问表达式时,如果遇到变量的使用,我们也需要在符号表中检查,避免使用未声明的变量。例如,如果我们将测例修改为:
int main() {
int x = 2026;
return x + y;
}
那么在扫描到加法操作的 AST 结点时,会依次检查该操作的两个操作数 x 和 y。这两个操作数均为变量标识符,因此我们需要到符号表中搜索 x 和 y 对应的符号。符号 x 可以在符号表中找到(我们在扫描 int x = 2026; 这条语句后已经为其定义),而 y 无法找到,因此编译器需要在扫描到 y 对应的结点时报错。
符号表总是和作用域相关的。例如,在 C 语言中,我们可以在全局作用域中定义名为 "a" 的全局变量,同时在 main 函数中定义名为 "a" 的局部变量,这并不产生冲突。不过由于本节还无需支持全局变量和块语句,同学们不用考虑这一点,只考虑 main 函数作用域对应的单张符号表即可。
此外,在本节中,我们引入了赋值操作。赋值可以看作一种特殊的二元运算,但需要注意,赋值号左侧必须为一个左值。具体来说,同学们需要检查赋值号左侧只能是变量名标识符。在 step11 中,我们会将左值的范围进一步包括数组元素。
对应到框架代码上:
frontend/symbol 目录下为符号的实现。其中 symbol.py 为符号类的基类,varsymbol.py 为变量符号。在本节中,同学们只需要考虑变量符号即可。
frontend/scope 目录下为符号表的实现。其中 scope.py 为作用域类,在本节中由于只有一个局部作用域,因此无需考虑作用域栈。同学们只需要新建一个 Scope 对象,用以维护 main 函数中所有出现过的变量符号即可。
中间代码生成
我们首先来看本节指导用例所对应的中间代码:
main:
_T1 = 2026
_T0 = _T1
return _T0
针对赋值操作,我们显然需要设计一条中间代码指令来表示它,给出的参考定义如下:
请注意,TAC 指令的名称只要在你的实现中是一致的即可,并不一定要和文档一致。
| 指令 | 参数 | 含义 |
|---|---|---|
ASSIGN |
T0,T1 |
临时变量的赋值 |
从中间代码可以看出,尽管我们引入了变量的概念,但是在比较低级的中间代码上,数据的存储和传递仍然是基于虚拟寄存器进行的。由于 MiniDecaf 语言中的基本类型只有 int 型,而 TAC 里的临时变量也是 32 位整数,因此,我们可以把 MiniDecaf 局部变量和 TAC 临时变量对应起来。
在扫描到 int x = 2026; 这条语句时,中间代码先把立即数 2026 加载到临时变量 _T1 中,然后再把 _T1 的值赋给临时变量 _T0,此时 _T0 已经成为了变量 x 的“替身”。每次需要用到变量 x 的值时,我们都会去访问 _T0。例如,测例中直接用返回 _T0 代替了返回变量 x 的值。因此,为了在后续使用变量 x 时能快速找到 _T0 这个临时变量,在符号表中存储 x 这个符号时,应当为该符号设置一个成员,存储 x 对应的临时变量。每当在 AST 上扫描到一个变量标识符结点时,我们都直接调用该变量对应的临时变量作为结点的返回值。
请注意 frontend/symbol/varsymbol.py 中,变量符号的定义里有该变量对应的 TAC 临时变量成员。
目标代码生成
本节指导用例对应如下 RISC-V 汇编代码:
.text
.global main
main:
li t1, 2026
mv t0, t1 # 我们使用 mv 指令来翻译中间表示里的 ASSIGN 指令
mv a0, t0
ret
简单的启发式寄存器分配算法
在中间代码中,我们使用了虚拟寄存器来存储变量的值。如果所使用的虚拟寄存器的个数,超过了目标机器实际拥有的物理寄存器数目,将无法生成正确的目标代码。此时,需要采用寄存器分配算法,调度和分配数目有限的物理寄存器资源,保证所有临时变量(虚拟寄存器或伪寄存器)都有合适的物理寄存器与之对应。在程序执行的任何时刻,都需要保证不会出现寄存器分配冲突,即两个同时有效且将被引用的临时变量(虚拟寄存器)被分配到同一个物理寄存器中,寄存器分配冲突将造成程序运行结果的错误。然而,寄存器分配问题是NP 完备问题(可以从 3-SAT 问题归约),这意味着对于一个含有大量临时变量的程序,为了获得最优寄存器分配方案,编译器将耗费可观的计算时间用于寄存器分配。因此,考虑到执行效率问题,实际的编译器实现中一般采用启发式算法。
实验框架中所采用的启发式寄存器分配算法基于活跃性分析。为避免一次性介绍过多的知识,将在 Step6 详细介绍活跃性分析的相关理论。大家目前只需要了解,活跃性分析是为了求解每个临时变量是否会在程序某点之后被引用,如果被引用,这个临时变量就是活跃的。 基于活跃性分析的启发式寄存器分配算法的基本思路:针对每一条 TAC 指令(例如 _T2 = ADD _T1, _T0),对于每个源操作数对应的临时变量(本例中 _T1 和 _T0),我们检查该临时变量是否已经存放在物理寄存器中,如果不是,则分配一个物理寄存器,并从栈帧中把该临时变量加载到寄存器中;对于目标操作数对应的临时变量(本例中的 _T2),如果该临时变量没有对应的物理寄存器,则为其分配一个新的物理寄存器。寄存器分配过程中,将为临时变量和为该变量分配的物理寄存器之间建立一种关联关系。 在分配寄存器时,首先检查是否存在空闲的寄存器(即尚未跟任何临时变量建立关联关系的寄存器),有则选择该寄存器作为分配结果。否则,检查有没有这样的寄存器,其所关联的临时变量在当前位置已经不是活跃变量了,这说明该寄存器所保存的数据未来不会被用到,可以回收使用这个寄存器而不用担心引起数据错误。一种可能的情况是,所有寄存器所关联的变量都是活跃的,即不存在空闲的寄存器。此时,将把某个寄存器所关联的暂时不用的变量存到栈帧(内存的一部分)中,腾出这个寄存器,这也称为溢出(spill)到内存。所腾空的寄存器是随机选取的,因此,所采用的寄存器分配算法有些暴力,存在进一步优化空间。
在实验框架中已经给出寄存器分配算法的代码,集中在 backend/reg/bruteregalloc.py 中,主要有以下几个函数:
accept:根据每个函数的 DFG(数据流图)进行寄存器分配,寄存器分配结束后生成相应汇编代码。bind:将一个 Temp(临时变量)与寄存器绑定。unbind:将一个 Temp(临时变量)与相应寄存器解绑定。localAlloc:根据活跃变量信息对一个 BasicBlock(基本块)内的指令进行寄存器分配。allocForLoc:每一条指令进行寄存器分配。allocRegFor:根据活跃变量信息决定为当前 Temp(临时变量)分配哪一个寄存器。
栈帧
上面的描述中提到,在分配寄存器的时候从栈帧中加载数据,以及将暂时不用的变量存储到栈帧中,接下来介绍栈帧的概念。
栈帧的概念
在汇编语言课程学习中,大家应该已经接触到栈帧的概念,下面简单回顾一下。在程序执行过程中,每次调用和执行一个函数,都会在栈上开辟一块新的存储空间,这块存储空间就叫做“栈帧”。栈帧中存放了函数执行所需的各种数据,包括需要临时保存的局部变量、在栈上临时申请的存储空间(如数组,在 Step11 中介绍)、被调用者负责保存的寄存器等。栈帧是函数正确调用和执行的保证。
需要注意的是,由于我们目前只支持一个 main 函数,直到 Step9 才会有多函数支持。所以现在关于栈帧的讨论,就只针对 main 函数的栈帧,并且集中于临时变量的存储和加载。
假设当前函数被某个函数调用,下图给出当前函数的栈帧。如图所示,当前函数的栈帧由被调用者负责保存的寄存器、保存的临时变量以及局部变量三个部分组成,fp 指向当前栈帧的栈底,sp 指向当前栈帧的栈顶,fp 和 sp 之间的部分就是当前函数的栈帧。当前实验步骤中,需要关注的是临时变量保存区域,正是在这个区域中,保存了为腾空物理寄存器而取出的临时变量(仍然活跃的临时变量)。值得一提的是,临时变量保存区域中还保存了基本块出口处仍活跃的临时变量(关于基本块的概念,将在 Step6 介绍,在当前的步骤不需要考虑)。
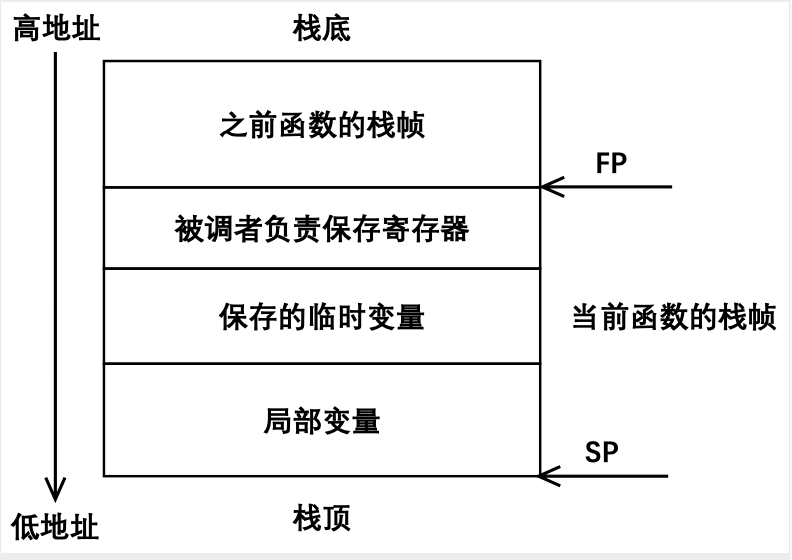
栈帧的建立与销毁
栈帧是函数运行所需要的上下文的一部分,在进入函数的时候需要建立对应的栈帧,在退出函数的时候需要销毁其对应的栈帧。栈帧对于函数的运行非常重要。那么程序在运行的过程中如何建立和销毁栈帧呢?实际上,建立栈帧的操作是由编译器生成代码完成的。在每个函数的起始位置,由编译器生成的用于建立栈帧的那段汇编代码称为函数的 prologue。prologue 所做的事情包括:分配栈帧空间和保存相应寄存器的值。相应的,在每个函数的末尾,用于销毁栈帧的那段汇编代码称为函数的 epilogue。epilogue 所做的事情包括:设置返回地址,回收栈帧空间,以及从当前被调用函数过程返回
貌似创建和销毁栈帧是一个大工程?实际不然,确定栈帧只需要维护好两个寄存器,sp 和 fp,它们分别保存当前栈帧的栈顶地址和栈底地址。当新的函数被调用时,需要把旧栈帧的栈底地址(fp)保存起来,用旧栈帧的栈顶地址(sp)表示新栈帧的栈底地址(新fp)。不难看出,新老栈帧在栈内存中是连续的存储空间。此外,每个函数体中需要分配的局部变量以及需要保存的临时变量在编译过程中是可知的。因此,栈帧的大小在编译期可以计算得出,即存储寄存器的空间,临时变量存储空间与局部变量空间三者之和。在求得栈帧大小之后,可以通过修改栈顶指针(sp)的值来分配恰当的栈帧空间。
一个例子
#include <stdio.h> int calculate() { int a = 1; int b = 2; int c = 3; int d = 4; int e = 5; int result = a + b + c + d + e; return result; } int main() { int result = calculate(); printf("%d\n", result); return 0; }在这个示例中,我们在 calculate 函数内部声明了 5 个局部整数变量(a 到 e)。假设我们的处理器只有 4 个通用寄存器,在这种情况下,我们无法将 5 个局部变量都保存在寄存器中。因此,编译器需要在栈上分配空间来存储这些变量。以下是栈空间的变化过程:
- main 函数调用 calculate 函数,将返回地址压入栈中。
- calculate 函数执行 prologue,将 fp 的值保存到栈中,然后将 sp 的值赋给 fp,此时 fp 和 sp 的值相同,都指向栈顶。
- calculate 函数分配栈帧空间,在这个例子中,假设 a 到 d 保存在寄存器中,e 保存在栈帧中,因此需要分配 4 字节的栈帧空间。sp 指向栈顶,因此 sp 的值减去 4,即可得到 e 的地址。
- 计算完成后,calculate 函数执行 epilogue,将 fp 的值赋给 sp,并恢复 fp 的值,然后将返回地址弹出栈中,跳转到返回地址。
思考题
请将你的整个stage-2作业放置在分支stage-2下,你可以通过git checkout -b stage-2创建一个新的分支并继承当前分支的修改。
- 我们假定当前栈帧的栈顶地址存储在 sp 寄存器中,请写出一段 risc-v 汇编代码,将栈帧空间扩大 16 字节。(提示1:栈帧由高地址向低地址延伸;提示2:risc-v 汇编中 addi reg0, reg1, <立即数> 表示将 reg1 的值加上立即数存储到 reg0 中。)
- 有些语言允许在同一个作用域中多次定义同名的变量,例如这是一段合法的 Rust 代码(你不需要精确了解它的含义,大致理解即可):
fn main() {
let a = 0;
let a = f(a);
let a = g(a);
}
其中f(a)中的a是上一行的let a = 0;定义的,g(a)中的a是上一行的let a = f(a);。
如果 MiniDecaf 也允许多次定义同名变量,并规定新的定义会覆盖之前的同名定义,请问在你的实现中,需要对定义变量和查找变量的逻辑做怎样的修改?(提示:如何区分一个作用域中不同位置的变量定义?)
总结
Step5 主要涉及的知识为符号表、寄存器分配和栈帧,对于大家来说有一定的跳跃性和挑战性,希望大家能够尽早开始。