step9 实验指导
本实验指导使用的例子为:
int func(int x, int y) {
return x + y;
}
int main() {
return func(1, 2);
}
词法语法分析
针对函数特性,我们需要设计 AST 节点来表示它,给出的参考定义如下:
| 节点 | 成员 | 含义 |
|---|---|---|
Function |
返回类型 return_type,函数名 ident,参数列表 params,函数体 body |
函数 |
Parameter |
参数类型 var_type,变量名 ident |
函数参数 |
Call |
调用函数名 ident,参数列表 argument_list |
函数调用 |
语义分析
本步骤中引入了函数,和局部变量类似,不允许调用未声明的函数,也不允许重复定义同名函数(允许重复声明,但要求声明类型一致)。因此,需要在全局作用域的符号表里维护函数符号。函数符号存放在栈底的全局作用域中,在遍历 AST 构建符号表的过程中,栈底符号表一直存在,不会被弹出。
此外,由于函数体内部除了局部变量以外,还有函数参数(argument)。因此,我们进入一个函数,开启函数体局部作用域时,需要将所有的参数加进该作用域的符号表中。举例来说,如果我们将示例改成:
int func(int x, int y) { int x = 1; return x + y; }
那么语义检查时应当报错。
函数符号的实现在 frontend/symbol/funcsymbol.py 中。
中间代码生成
为了实现函数,我们需要设计至少一条中间代码指令来表示函数调用,给出的参考定义如下(推荐大家这样实现):
请注意,TAC 指令的名称只要在你的实现中是一致的即可,并不一定要和文档一致。
| 指令 | 参数 | 含义 |
|---|---|---|
CALL |
LABEL(T0, T1, ...) |
调用函数 LABEL,传入的实参为T0、T1等 |
下面是一段含有函数调用的代码片段:
T0 = CALL foo(T1, T2)
T1和T2作为被调用函数foo的实参,而调用后的返回值保存在T0中。
示例可以对应如下的 TAC 程序:
func:
_T2 = ADD _T0, _T1
return _T2 # 参数 x 和 y 分别对应 _T0, _T1
main:
_T0 = 1
_T1 = 2
_T2 = CALL func(_T0, _T1) # 调用函数
return _T2
实际上这与高级语言的函数语义非常相似。你可能会觉得一个与源语言语义几乎没差别的中间代码函数调用指令有点多余,所以我们也提供了另一种方案(不推荐按照这样实现,可能会造成数据流分析困难)。
在早先的文档中,函数调用涉及
CALL和PARAM两种指令。CALL指令只对应实际汇编代码的函数调用,而PARAM T0指令用于传递一个参数。假设我们有若干个参数,可以依次使用 PARAM 命令将它们加入参数列表。在调用函数时,这些参数的值会自动依次按顺序装载到临时变量 _T0, _T1 ... 中。比如我们有这样一段 TAC 程序:
PARAM A
PARAM B
PARAM C
XX = CALL XXX
因此,示例可以对应如下的 TAC 程序:
func:
_T2 = ADD _T0, _T1
return _T2 # 参数 x 和 y 分别对应 _T0, _T1
main:
_T0 = 1
PARAM _T0 # 将 _T0 的值作为参数 x
_T1 = 2
PARAM _T1 # 将 _T1 的值作为参数 y
_T3 = CALL func # 调用函数
return _T3
同学们可以选择使用这两种方案中的任何一种,也可以自行设计函数调用的中间表示。
思考
在本次实验中我们设置了一道关于函数调用中间表示设计的思考题。下面的问题或许能帮助你思考(你无需回答这里的问题,这里也没有标准答案):
- 中间表示应该更接近源语言(高级语言)还是目标语言(例如汇编语言)?
- 到目前为止实验文档给出的参考中间表示更接近源语言还是目标语言?
如果你感兴趣,可以了解一下LLVM IR。
目标代码生成
下面是一种可能的目标汇编代码,你的编译器生成的代码无需与其完全一致。
.text
.global main
func:
# start of prologue
addi sp, sp, -56
# end of prologue
# start of body
add t0, a0, a1
mv a0, t0
j func_exit
# end of body
func_exit:
# start of epilogue
addi sp, sp, 56
# end of epilogue
ret
main:
# start of prologue
addi sp, sp, -56
sw ra, 52(sp)
# end of prologue
# start of body
li t0, 1
li t1, 2
mv a0, t0
mv a1, t1
call func
mv t0, a0
mv a0, t0
j main_exit
# end of body
main_exit:
# start of epilogue
lw ra, 52(sp)
addi sp, sp, 56
# end of epilogue
ret
首先你需要参考之前步骤中实现的方法,翻译本步骤中新增的中间代码指令。
完成这个步骤的过程中你可能需要回顾step 2中对于后端翻译的介绍和step 5中对于寄存器分配和栈帧的介绍来回想一下后端每个部分在做什么。
函数调用
程序代码里的一个函数调用,包含了下面一系列的操作:
- (汇编)保存 caller-saved 寄存器。
- 准备参数,完成传参。
- 执行汇编中的函数调用指令,开始执行子函数直至其返回。
- 拿到函数调用的返回值,作为函数调用表达式的值。
- 具体依赖于1的处理方式,可能需要恢复 caller-saved 寄存器。
上述步骤 1-5 称为调用序列(calling sequence)。然而,调用序列中有一些问题需要解决:如何进行参数传递?如何获取函数返回值?调用者(caller)和被调用者(callee)需要保存哪些寄存器,如何保存?调用者和被调用者通常对以上问题约定解决方式,并同时遵守这些约定。这些调用者与被调用者共同遵守的约定称为调用约定(calling convention)。调用约定通常在汇编层级使用,汇编语言课上也有涉及。因为汇编语言是低级语言,缺乏对函数的语言特性支持,只有标号、地址、寄存器,所以需要调用约定,规定如何用汇编的语言机制实现函数调用。
调用约定
我们给出RISC-V标准调用约定供大家参考,你可以不按照标准调用约定实现,这样的话你需要自己定义一种调用约定。如果你实现的是标准调用约定,你的编译器生成的代码还可以与gcc生成的代码进行链接,比如链接标准库,实现输入输出等功能。
RISC-V 的标准调用约定
caller-saved 和 callee-saved 寄存器
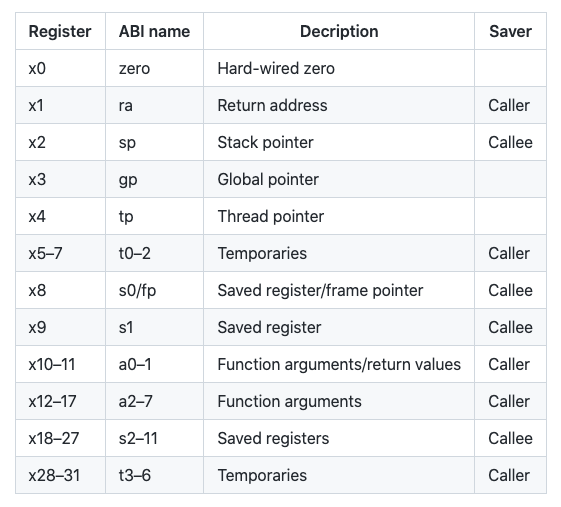
上表给出 RISC-V 中 32 个整数寄存器的分类。所谓 caller-saved 寄存器(又名易失性寄存器),是指不需要在各个调用之间保存的寄存器,如果调用者认为在被调用函数执行结束后仍然需要用到这些寄存器中的值,则需要自行保存。所谓 callee-saved 寄存器(又名非易失性寄存器),指这些寄存器需要在各个调用之间保存,调用者可以期望在被调用函数执行结束后,这些寄存器仍保持原来的值。这要求被调用者,如果使用这些寄存器,需要先进行保存,并在调用返回之前恢复这些 callee-saved 寄存器的值。
具体的保存方法并不限制,但一般都使用栈来保存。
函数参数以及返回值的传递
函数参数(32 位 int)从左到右存放在 a0 - a7 寄存器中,如果还有其他参数,则以从右向左的顺序压栈,第 9 个参数在栈顶位置。同学们可以使用编写一个带有多个参数的函数并进行调用,然后用 gcc 编译程序进行验证。
返回值(32 位 int)放在 a0 寄存器中。
实战教学
我们推荐大家按照以下步骤实现,当然这不是唯一的实现方式。前中端的部分在前面的step中涉及很多,大家应该已经比较熟悉,这里着重关注后端要做的事。
要做什么
由于调用约定的存在,中间表示里的函数调用指令无法像我们之前接触到的常规指令一样简单地翻译为实际汇编指令,我们必须生成额外代码进行寄存器保存、参数传递等操作以符合调用约定。这些额外操作会出现在真正的函数调用指令call周围,我们称之为“(生成)函数调用时的处理”或“对于调用者的处理”。
只是让caller调用函数的过程遵循调用约定还不够,被调用的每个函数callee也要遵守规范,保存恢复callee-saved寄存器、从正确的位置获取caller传入的参数。因为每个函数都是(潜在的)被调用者,故对于所有函数都要生成这些操作。我们称之为“生成函数体时的处理”或“对于被调用者的处理”。
你在后端主要需要实现的即为“对于调用者的处理”与“对于被调用者的处理”两部分。
对于调用者的处理
这里我们需要关注源文件backend/reg/bruteregalloc.py中的BruteRegAlloc类。
根据调用约定,调用其它函数后caller-saved即volatile寄存器中的值全部是无效的。这意味着如果函数调用前caller-saved寄存器中存放了后续仍活跃的临时变量,它们必须被倒腾到别的地方,如callee-saved寄存器或栈上。因此我们先将活跃且在caller-saved寄存器中的临时变量保存到栈上,这实际上让所有caller-saved寄存器变得空闲,以便于接下来在a0到a7中容纳参数。
保存活跃的临时变量:首先保存所有位于caller-saved寄存器中且活跃的临时变量,然后解除所有caller-saved寄存器与临时变量的绑定关系。你可以用
subEmitter.emitStoreToStack和unbind来达到上述效果。这是否意味着原本就在caller-saved寄存器中的参数也被丢到了栈上?似乎有些多余?
是的,但这样处理比较简单。比较理想的方案是直接将参数从一个寄存器复制到目标参数寄存器,但这可能带来一些边角情况,你需要谨慎处理。
将参数放入寄存器:所有传参用到的寄存器(
a0~a7)都是caller-saved寄存器,1中的操作保证了传参所需要的寄存器都是空的,因此直接将参数放到寄存器中即可。具体地,用物理寄存器a0~a7传递被调用函数的前8个参数,我们假设这8个参数对应的临时变量(Temp)为v0~v7。对于第i个参数,目标是将vi的值加载入ai。若vi已经与某个物理寄存器xj绑定,则可以生成指令mv ai, xj;如果vi的值不在物理寄存器中,调用emitLoadFromStack。(思考: 如果前面暂时不解除volatile寄存器的绑定,这里可能会有什么问题? 你有更高效的解决方案吗?)为什么有的临时变量可能在寄存器中?
因为我们在步骤1中只操作了caller-saved寄存器。如果某个临时变量存放在callee-saved寄存器中,那么它不会在上一步骤被放到栈上。
用栈传递参数(可选):调用约定规定
a0至a7存放不下的参数需要用栈传递(为了降低大家的实现难度,基础实验中我们不对参数超过8个的传参实现进行测试)。若参数vi在物理寄存器xj中,则直接将xj“压栈”;否则任选一个a0~a7之外的volatile寄存器tk,我们先通过emitLoadFromStack将vi加载到tk,然后“压栈”tk(建议直接使用t0寄存器)。需要注意这里的“压栈”不能直接用emitStoreToStack,我们需要手动生成一条NativeStoreWord指令,而且它无需也不应该修改栈指针sp。在所有参数入栈后,统一修改sp。进行真正的函数调用:可以使用
emitAsm来生成一条调用指令。如果上一步中存在栈传参,别忘了在调用后把sp改回来(清除栈上传递的参数)。妥善处理函数返回值:根据调用约定,函数返回值会存放在
a0寄存器中。如果你在指令选择中为函数调用单独增添了将a0复制到目标临时变量的指令,这里无需处理。你也可以选择直接将目标临时变量绑定到a0。记录函数调用情况(可选):你也许需要在
SubroutineEmitter中记录当前函数是否调用过其它函数,以便减少不必要的ra保存和恢复。
对于被调用者的处理
这里我们需要关注源文件backend/riscv/riscvasmemitter.py中的RiscvSubroutineEmitter类和backend/reg/bruteregalloc.py中的BruteRegAlloc类。被调用者需要从正确的位置获取到传入的参数,因此需要处理寄存器和临时变量的对应关系;同时在被调用函数的结尾我们要准确无误地返回到调用处,因此需要处理和返回地址相关的信息。
处理返回地址:具体需要保存和恢复
ra寄存器,相关实现在emitFunc函数中。框架的现有部分已经帮助大家处理好了callee-saved寄存器的保存和恢复,你可以参照这部分实现ra寄存器的保存和恢复。(备注:严格来讲ra并不是callee-saved寄存器。ra会在什么情况下被修改?不过你可以选择总是保存和恢复ra。)处理传入的函数参数和临时变量的对应关系:将传入的参数与临时变量绑定,这样在函数体中就可以直接使用这些参数。
BruteRegAlloc类中的的bindings变量记录了临时变量和物理寄存器的对应关系,你可以使用bind,unbind函数来完成这些操作。思考应该在何处进行这个绑定操作。
一些可能带来困惑的地方
ra是一个caller-saved寄存器,但它有着和callee-saved寄存器相似的处理方式。一般而言只有当某个函数作为caller调用了其它函数时,它存放在ra中的返回地址才会被覆盖掉,这与其它caller-saved寄存器类似。然而鉴于ra的特殊用途,你可以把它视作一个callee-saved寄存器。你可能会发现我们的框架能支持的栈空间大小有限,存放不了太多的临时变量。目前而言的确是这样,你无需考虑那种情况。
思考题
你更倾向采纳哪一种中间表示中的函数调用指令的设计(一整条函数调用 vs 传参和调用分离)?写一些你认为两种设计方案各自的优劣之处。
具体而言,某个“一整条函数调用”的中间表示大致如下:
_T3 = CALL foo(_T2, _T1, _T0)对应的“传参和调用分离”的中间表示类似于:
PARAM _T2 PARAM _T1 PARAM _T0 _T3 = CALL foo为何 RISC-V 标准调用约定中要引入 callee-saved 和 caller-saved 两类寄存器,而不是要求所有寄存器完全由 caller/callee 中的一方保存?为何保存返回地址的 ra 寄存器是 caller-saved 寄存器?
总结
到这里,你已经完成了所有基础实验。有了对函数的支持,你的编译器也变得更加强大,你可以试着用它写一些更有意思的代码。